1. Objective
During disasters, communication is vital, but it is at such times that disaster response organizations are least able to filter and extract the most important messages.
The objective of this project is to classify messages into several categories to indicate to which organizations they should be referred.
For this, I use real anonymized messages sent during disaster events provided by Udacity, in collaboration with Appen (formally Figure 8), as a part of their Data Scientist Nanodegree Program.
2. Overview
- Merged and cleaned data from files into a SQLite database (ETL process)
- Applied a Machine Learning pipeline containg NLTK features, a custome tokenizer to handle text, and a classification model able to handle multioutput tasks
- Introduced grid search cross validation on hyperparameters to the ML pipeline to be able to not only fine-tune the ML model but also the preprocessing steps to handle text data
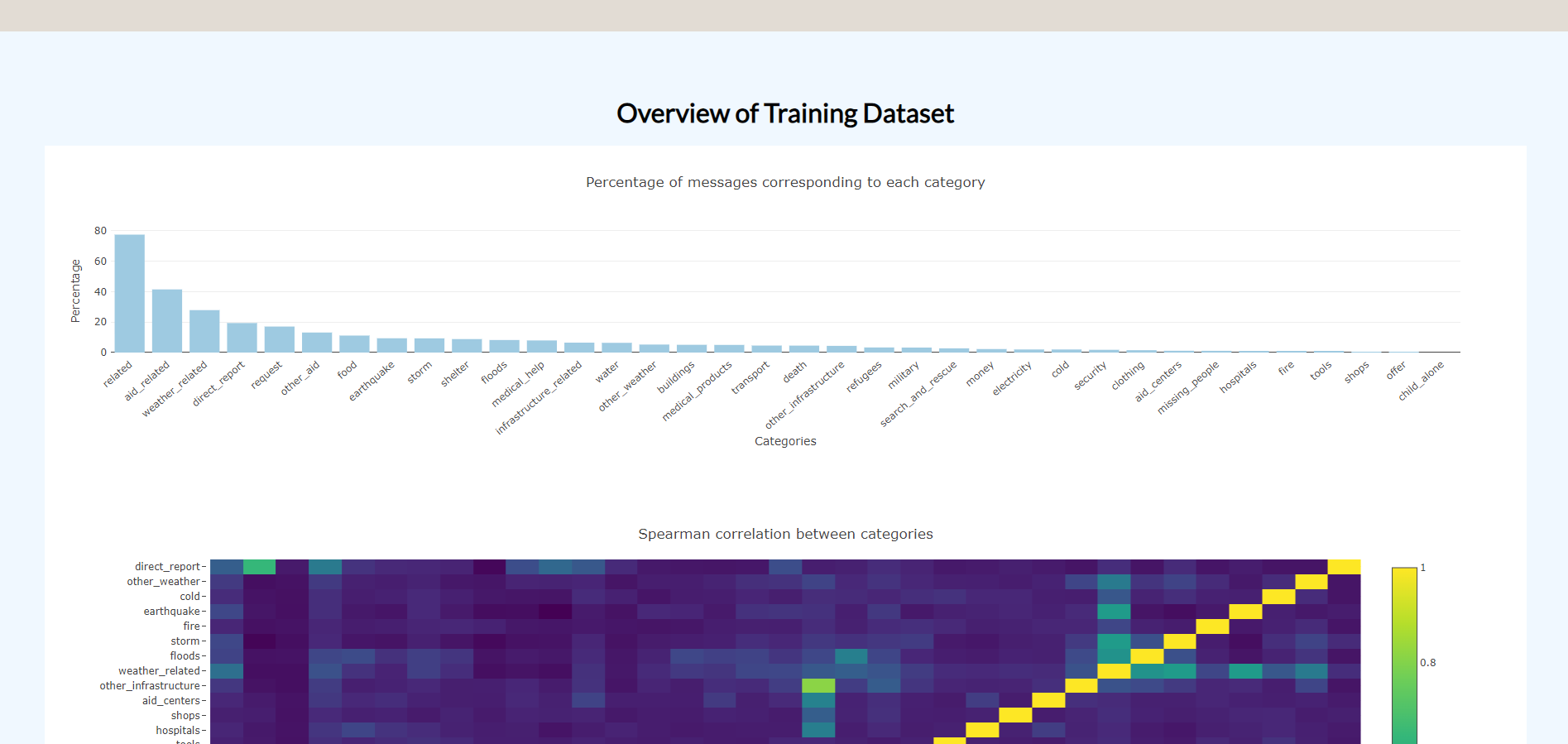
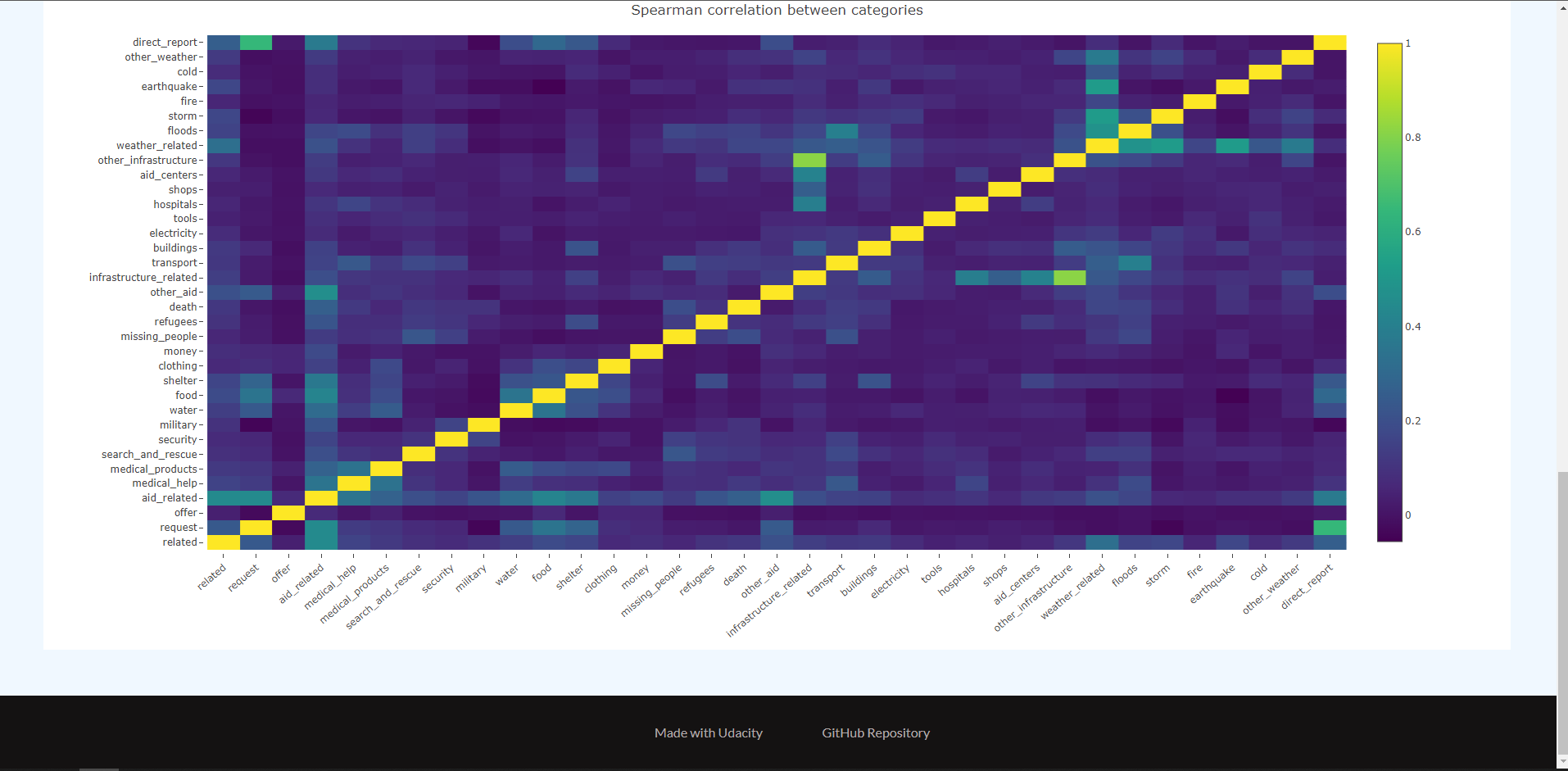
- Built a web application using Flask that lets users input a message to be classified by the model (runs locally) and display Plotly figures created with data from the SQLite database